

ZK spécialisé ou ZK général : quel est l’avenir ?
Spécialisation et généralisation, lequel des deux est l’avenir de ZK ? Je vais tenter de répondre à cette question à l’aide d’un diagramme :
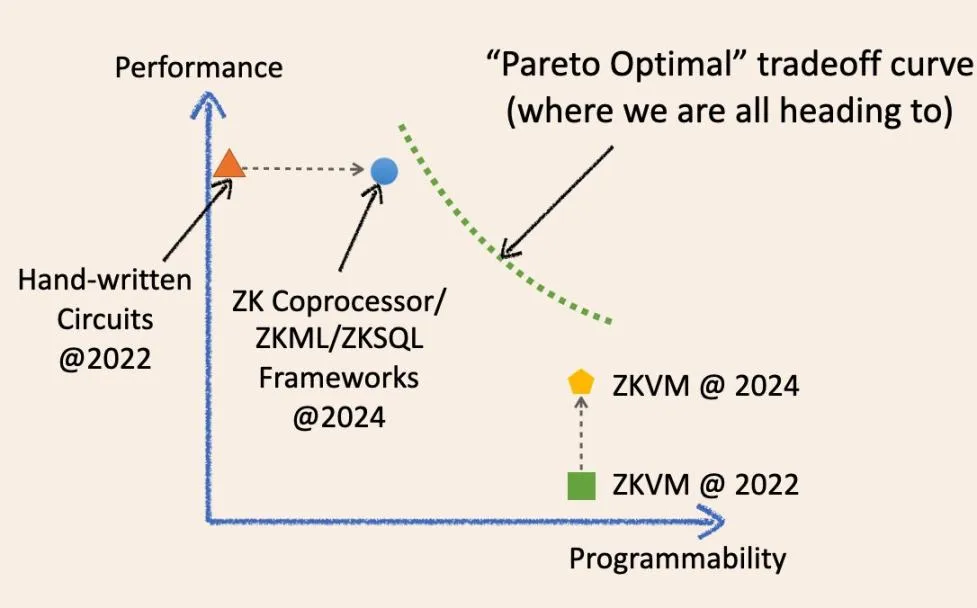
Comme le montre le diagramme, est-il possible de converger à l’avenir vers un point optimal magique sur le système de coordonnées du compromis ?
Non, l’avenir de l’informatique vérifiable hors chaîne est une courbe continue qui brouille les frontières entre le ZK spécialisé et le ZK général. Permettez-moi d’expliquer l’évolution historique de ces termes et la manière dont ils convergeront à l’avenir.
Il y a deux ans, une infrastructure ZK « spécialisée » signifiait des cadres de circuits de bas niveau tels que circom, Halo2 et arkworks. Les applications ZK construites à l’aide de ces cadres étaient essentiellement des circuits ZK écrits à la main. Ils étaient rapides et rentables pour des tâches spécifiques, mais généralement difficiles à développer et à maintenir. Ils s’apparentent à divers circuits intégrés spécialisés (plaquettes de silicium physiques) dans l’industrie des circuits intégrés d’aujourd’hui, tels que les puces NAND et les puces de contrôleur.
Toutefois, au cours des deux dernières années, l’infrastructure spécialisée ZK s’est progressivement « généralisée ».
Nous disposons désormais des cadres ZKML, ZK coprocesseur et ZKSQL qui offrent des SDK faciles à utiliser et hautement programmables pour créer différentes catégories d’applications ZK sans écrire une seule ligne de code de circuit ZK. Par exemple, le coprocesseur ZK permet aux contrats intelligents d’accéder en toute confiance aux états, événements et transactions historiques de la blockchain et d’exécuter des calculs arbitraires sur ces données. ZKML permet aux contrats intelligents d’utiliser les résultats de l’inférence de l’IA de manière transparente pour gérer un large éventail de modèles d’apprentissage automatique.
Ces cadres évolués améliorent considérablement la programmabilité dans leurs domaines cibles tout en maintenant des performances élevées et un faible coût grâce à des couches d’abstraction fines (SDK/API) qui sont proches des circuits à l’état brut.
Ils sont comparables aux GPU, TPU et FPGA sur le marché des circuits intégrés : des spécialistes des domaines programmables.
ZKVM a également fait de grands progrès au cours des deux dernières années. Notamment, toutes les ZKVM à usage général sont construites sur des frameworks ZK spécialisés de bas niveau. L’idée est que vous pouvez écrire des applications ZK dans des langages de haut niveau (encore plus conviviaux que le SDK/API), qui se compilent dans une combinaison de circuits spécialisés et de jeux d’instructions (RISC-V ou similaire à WASM). Ils sont comme les puces CPU dans l’industrie des circuits intégrés.
ZKVM est une couche d’abstraction au-dessus des cadres ZK de bas niveau, tout comme les coprocesseurs ZK.
Comme l’a dit un jour un sage, une couche d’abstraction peut résoudre tous les problèmes informatiques, mais elle crée en même temps un autre problème. Les compromis, voilà la clé. Fondamentalement, pour ZKVM, nous faisons un compromis entre performance et généralité.
Il y a deux ans, les performances « bare-metal » de ZKVM étaient effectivement médiocres. Cependant, en l’espace de deux ans, les performances de ZKVM se sont considérablement améliorées.
Pourquoi ?
En effet, ces ZKVM « à usage général » sont devenues plus « spécialisées ». L’une des principales raisons de l’amélioration des performances est la « précompilation ». Ces précompilations sont des circuits ZK spécialisés capables de calculer des programmes de haut niveau courants, tels que SHA2 et diverses vérifications de signature, beaucoup plus rapidement qu’en les décomposant en fragments de circuits d’instructions.
La tendance est donc désormais très claire.
Les infrastructures ZK spécialisées se généralisent, tandis que les ZKVM générales se spécialisent.
Les optimisations des deux solutions au cours des dernières années ont permis d’atteindre un meilleur compromis qu’auparavant : progresser sur un point sans en sacrifier un autre. C’est pourquoi les deux parties ont le sentiment que « nous sommes définitivement l’avenir ».
Cependant, la sagesse informatique nous dit qu’à un moment donné, nous rencontrerons le « mur optimal de Pareto » (ligne verte en pointillés), où nous ne pouvons pas améliorer une performance sans en sacrifier une autre.
Une question à un million de dollars se pose donc :
Une technologie remplacera-t-elle complètement une autre au moment opportun ?
Si l’on se réfère à l’industrie des circuits intégrés, la taille du marché des processeurs est de 126 milliards de dollars, tandis que l’ensemble de l’industrie des circuits intégrés (y compris tous les circuits « spécialisés ») représente 515 milliards de dollars. Je suis convaincu que, d’un point de vue microéconomique, l’histoire se répétera et que les deux produits ne se remplaceront pas l’un l’autre.
Cela étant dit, personne ne dirait aujourd’hui : « J’utilise un ordinateur entièrement piloté par une unité centrale polyvalente » ou « C’est un robot sophistiqué piloté par des circuits intégrés spécialisés ».
Oui, nous devrions en effet considérer cette question d’un point de vue macroéconomique et, à l’avenir, il y aura une courbe de compromis permettant aux développeurs de choisir de manière flexible en fonction de leurs besoins.
À l’avenir, l’infrastructure ZK spécialisée et la ZKVM générale pourront fonctionner ensemble. Cela peut se faire sous plusieurs formes. La méthode la plus simple est déjà réalisable aujourd’hui. Par exemple, vous pouvez utiliser un coprocesseur ZK pour générer des résultats de calcul dans l’historique des transactions de la blockchain, mais la logique de calcul sur ces données est très complexe et ne peut pas être simplement exprimée dans le SDK/API.
Ce que vous pouvez faire, c’est obtenir des preuves ZK performantes et peu coûteuses des données et des résultats de calculs intermédiaires, puis les agréger dans une VM polyvalente par le biais de preuves récursives.
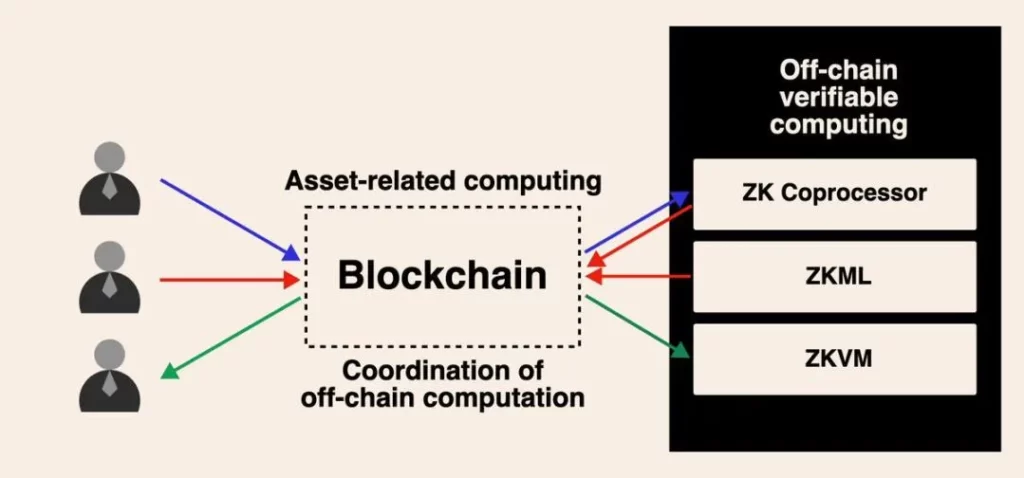
Bien que je trouve ce genre de débat intéressant, je sais que nous sommes tous en train de construire cet avenir informatique asynchrone piloté par un calcul vérifiable hors chaîne pour blockchain. Au fur et à mesure que les cas d’utilisation pour une adoption massive par les utilisateurs émergeront dans les années à venir, je pense que ce débat atteindra finalement une conclusion.