Specialization and generalization, which one is the future of ZK? Let me try to answer this question with a diagram:

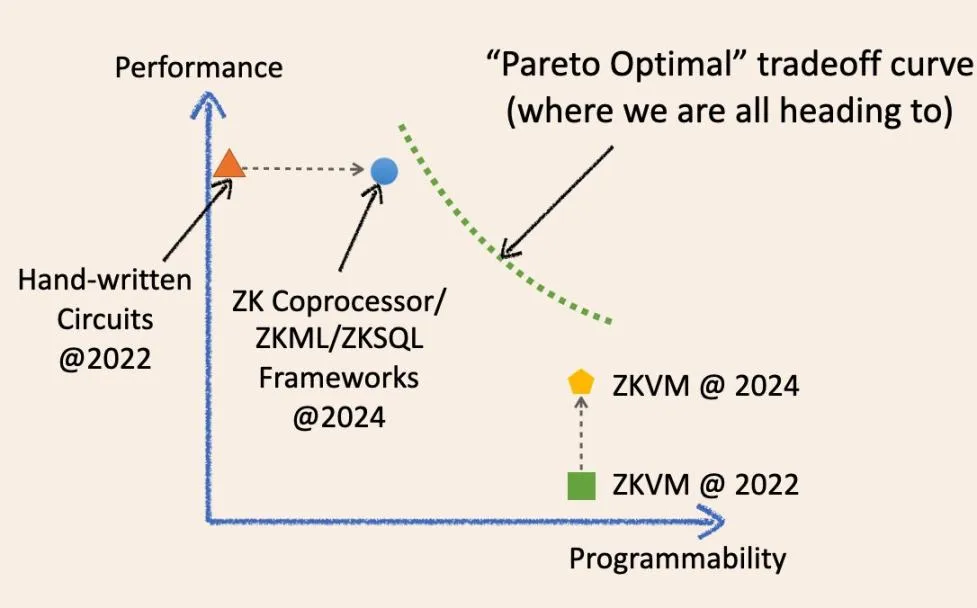
As shown in the diagram, is it possible for us to converge to a magical optimal point on the trade-off coordinate system in the future?
No, the future of off-chain verifiable computation is a continuous curve that blurs the boundaries between specialized and general ZK. Allow me to explain the historical evolution of these terms and how they will converge in the future.
Two years ago, “specialized” ZK infrastructure meant low-level circuit frameworks like circom, Halo2, and arkworks. ZK applications built using these frameworks were essentially hand-written ZK circuits. They were fast and cost-effective for specific tasks but typically difficult to develop and maintain. They are akin to various specialized integrated circuit chips (physical silicon wafers) in today’s IC industry, such as NAND chips and controller chips.
However, over the past two years, specialized ZK infrastructure has gradually become more “generalized.”
We now have ZKML, ZK coprocessor, and ZKSQL frameworks that offer easy-to-use and highly programmable SDKs for building different categories of ZK applications without writing a single line of ZK circuit code. For instance, the ZK coprocessor allows smart contracts to trustlessly access blockchain historical states, events, and transactions and run arbitrary computations on this data. ZKML enables smart contracts to utilize AI inference results in a trustless manner to handle a wide range of machine learning models.
These evolved frameworks significantly improve programmability in their target domains while maintaining high performance and low cost due to thin abstraction layers (SDK/API) that are close to bare-metal circuits.
They are akin to GPU, TPU, and FPGA in the IC market: programmable domain specialists.
ZKVM has also made great strides over the past two years. Notably, all general-purpose ZKVMs are built on top of low-level, specialized ZK frameworks. The idea is that you can write ZK applications in high-level languages (even more user-friendly than SDK/API), which compile into a combination of specialized circuits and instruction sets (RISC-V or similar to WASM). They are like CPU chips in the IC industry.
ZKVM is an abstraction layer above low-level ZK frameworks, just like ZK coprocessors.
As a wise person once said, an abstraction layer can solve all computer science problems but simultaneously creates another problem. Trade-offs, that’s the key. Fundamentally, for ZKVM, we trade off performance and generality.
Two years ago, the “bare-metal” performance of ZKVM was indeed poor. However, in just two years, the performance of ZKVM has significantly improved.
Why?
Because these “general-purpose” ZKVMs have become more “specialized.” A key reason for performance improvement is “precompilation.” These precompilations are specialized ZK circuits capable of computing common high-level programs, such as SHA2 and various signature verifications, much faster than breaking them down into instruction circuit fragments.
Thus, the trend is now quite clear.
Specialized ZK infrastructure is becoming more generalized, while general ZKVMs are becoming more specialized.
The optimizations of both solutions over the past few years have achieved a better trade-off point than before: making progress on one point without sacrificing another. That’s why both sides feel “we are definitely the future.”
However, computer science wisdom tells us that at some point, we will encounter the “Pareto optimal wall” (green dashed line), where we cannot improve one performance without sacrificing another.
Therefore, a million-dollar question arises:
Will one technology completely replace another at the right time?
Borrowing insights from the IC industry: the CPU market size is $126 billion, while the entire IC industry (including all “specialized” ICs) is $515 billion. I am confident that, from a micro perspective, history will repeat itself here, and they will not replace each other.
That being said, today no one would say, “Hey, I’m using a computer entirely driven by a general-purpose CPU,” or “Hey, this is a fancy robot driven by specialized ICs.”
Yes, we should indeed view this issue from a macro perspective, and in the future, there will be a trade-off curve allowing developers to flexibly choose according to their needs.
In the future, specialized ZK infrastructure and general ZKVM can work together. This can be realized in multiple forms. The simplest method is already achievable now. For instance, you can use a ZK coprocessor to generate some computation results in the blockchain transaction history, but the computation business logic on this data is very complex and cannot be simply expressed in the SDK/API.
What you can do is obtain high-performance and low-cost ZK proofs of the data and intermediate computation results, then aggregate them into a general-purpose VM through recursive proofs.

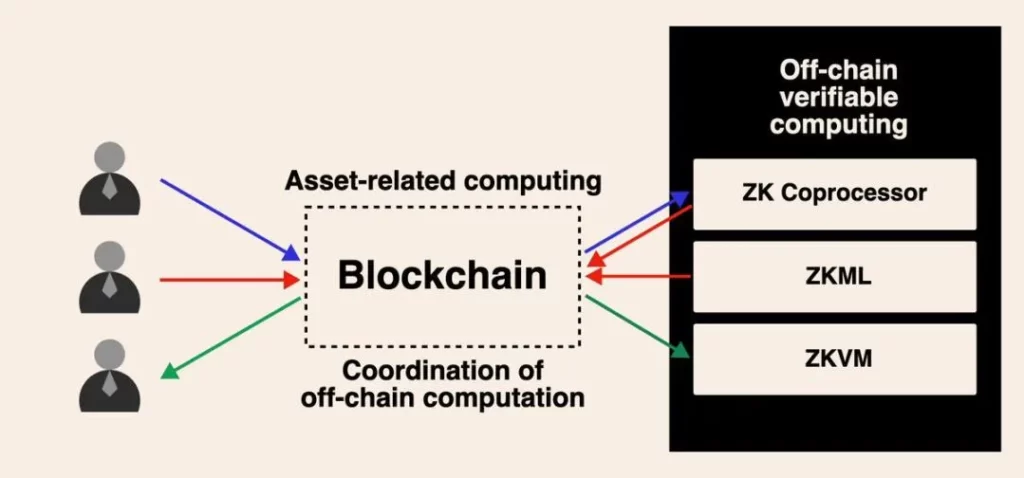
While I find this kind of debate interesting, I know we are all building this asynchronous computing future driven by off-chain verifiable computation for blockchain. As use cases for mass user adoption emerge in the coming years, I believe this debate will finally reach a conclusion.
-

-

-

-

-

-

-

-

