Специализация и обобщение — за кем из них будущее ZK? Позвольте мне попытаться ответить на этот вопрос с помощью диаграммы:

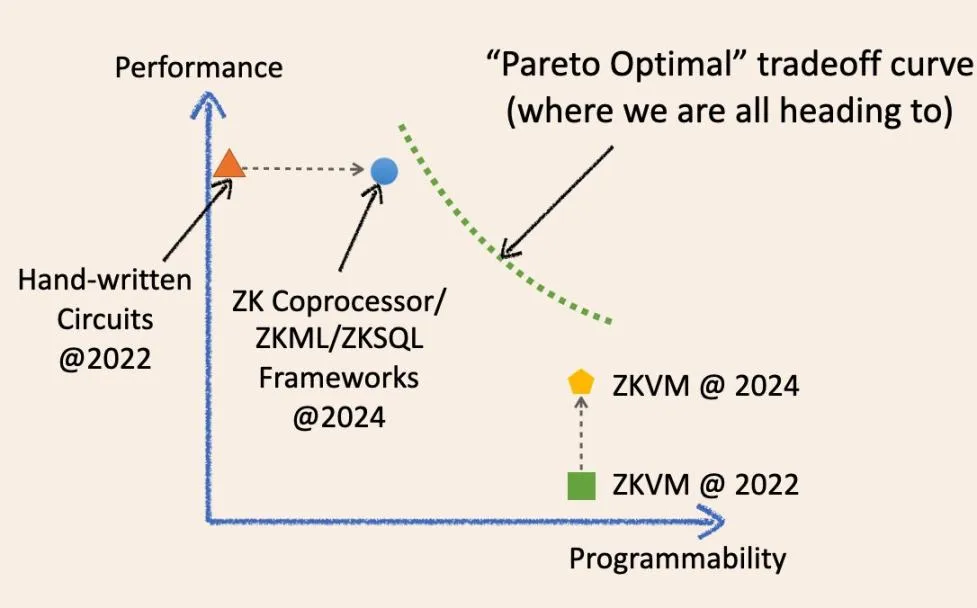
Как показано на диаграмме, возможно ли, что в будущем мы придем к магически оптимальной точке в системе координат компромисса?
Нет, будущее верифицируемых вычислений вне цепи — это непрерывная кривая, которая стирает границы между специализированными и общими ЗК. Позвольте мне объяснить историческую эволюцию этих терминов и то, как они будут сходиться в будущем.
Два года назад под «специализированной» инфраструктурой ZK подразумевались низкоуровневые схемотехнические фреймворки, такие как circom, Halo2 и arkworks. ZK-приложения, созданные с использованием этих фреймворков, по сути, представляли собой написанные вручную ZK-схемы. Они были быстрыми и экономичными для решения конкретных задач, но, как правило, сложными в разработке и сопровождении. Они похожи на различные специализированные микросхемы интегральных схем (физические кремниевые пластины) в современной индустрии ИС, такие как микросхемы NAND и микросхемы контроллеров.
Однако за последние два года специализированная инфраструктура ZK постепенно стала более «обобщенной».
Теперь у нас есть фреймворки ZKML, сопроцессор ZK и ZKSQL, которые предлагают простые в использовании и высокопрограммируемые SDK для создания различных категорий приложений ZK без написания ни одной строки кода схемы ZK. Например, сопроцессор ZK позволяет смарт-контрактам без доверия получать доступ к историческим состояниям, событиям и транзакциям блокчейна и выполнять произвольные вычисления на этих данных. ZKML позволяет смарт-контрактам использовать результаты выводов искусственного интеллекта в недоверенной манере для работы с широким спектром моделей машинного обучения.
Эти развитые фреймворки значительно улучшают программируемость в своих целевых областях, сохраняя при этом высокую производительность и низкую стоимость благодаря тонким слоям абстракции (SDK/API), близким к пустым схемам.
Они сродни GPU, TPU и FPGA на рынке ИС: специалисты по программируемым областям.
За последние два года ZKVM также добилась значительных успехов. Примечательно, что все ZKVM общего назначения построены поверх низкоуровневых специализированных фреймворков ZK. Идея заключается в том, что вы можете писать ZK-приложения на языках высокого уровня (даже более удобных, чем SDK/API), которые компилируются в комбинацию специализированных схем и наборов инструкций (RISC-V или аналогичных WASM). Они подобны процессорным чипам в индустрии ИС.
ZKVM — это уровень абстракции над низкоуровневыми ZK-фреймворками, как и ZK-сопроцессоры.
Как сказал один мудрый человек, слой абстракции может решить все проблемы компьютерной науки, но одновременно создает еще одну проблему. Компромиссы — вот ключевой момент. По сути, в ZKVM мы идем на компромисс между производительностью и универсальностью.
Два года назад производительность ZKVM на «голом железе» была действительно низкой. Однако всего за два года производительность ZKVM значительно повысилась.
Почему?
Потому что эти «универсальные» ZKVM стали более «специализированными». Ключевой причиной повышения производительности является «прекомпиляция». Эти прекомпиляции представляют собой специализированные схемы ZK, способные вычислять обычные высокоуровневые программы, такие как SHA2 и различные проверки подписей, гораздо быстрее, чем разбивать их на фрагменты схем инструкций.
Таким образом, тенденция теперь вполне очевидна.
Специализированная инфраструктура ZK становится все более обобщенной, а общие ZKVM — все более специализированными.
Оптимизация обоих решений за последние несколько лет позволила достичь лучшего компромисса, чем раньше: прогресс в одной области без ущерба для другой. Вот почему обе стороны считают, что «за нами будущее».
Однако мудрость компьютерной науки говорит нам, что в какой-то момент мы столкнемся с «стеной оптимальности Парето» (зеленая пунктирная линия), когда мы не сможем улучшить одну производительность, не жертвуя другой.
Поэтому возникает вопрос на миллион долларов:
Сможет ли одна технология полностью заменить другую в нужный момент?
Заимствуя опыт индустрии интегральных схем: объем рынка процессоров составляет 126 миллиардов долларов, а всей индустрии интегральных схем (включая все «специализированные» ИС) — 515 миллиардов долларов. Я уверен, что с микроперспективы история повторится и здесь, и они не заменят друг друга.
Тем не менее, сегодня никто не скажет: «Эй, я использую компьютер, полностью управляемый процессором общего назначения» или «Эй, это модный робот, управляемый специализированными микросхемами».
Да, мы действительно должны рассматривать этот вопрос с макроперспективы, и в будущем будет существовать кривая компромисса, позволяющая разработчикам гибко выбирать в соответствии с их потребностями.
В будущем специализированная инфраструктура ZK и общая ZKVM могут работать вместе. Это может быть реализовано в разных формах. Самый простой способ достижим уже сейчас. Например, вы можете использовать сопроцессор ZK для генерации некоторых результатов вычислений в истории транзакций блокчейна, но бизнес-логика вычислений на этих данных очень сложна и не может быть просто выражена в SDK/API.
Что можно сделать, так это получить высокопроизводительные и недорогие ZK-доказательства данных и промежуточных результатов вычислений, а затем объединить их в ВМ общего назначения с помощью рекурсивных доказательств.

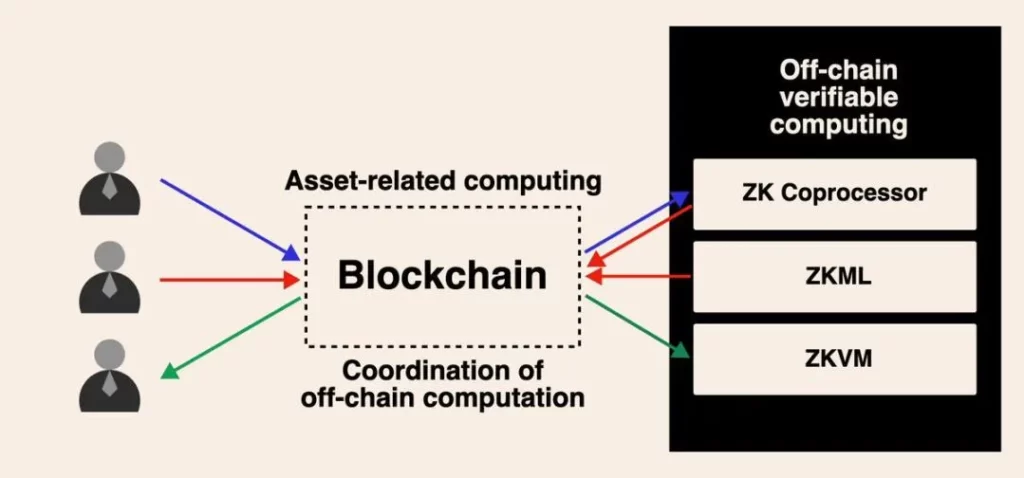
Хотя я нахожу подобные дебаты интересными, я знаю, что мы все строим это асинхронное вычислительное будущее, управляемое верифицируемыми вычислениями вне цепи для блокчейн. По мере того как в ближайшие годы будут появляться сценарии массового использования, я верю, что эта дискуссия наконец-то завершится.
-

-

-

-

-

-

-

-

