Especialização e generalização, qual é o futuro da ZK? Vou tentar responder a essa pergunta com um diagrama:

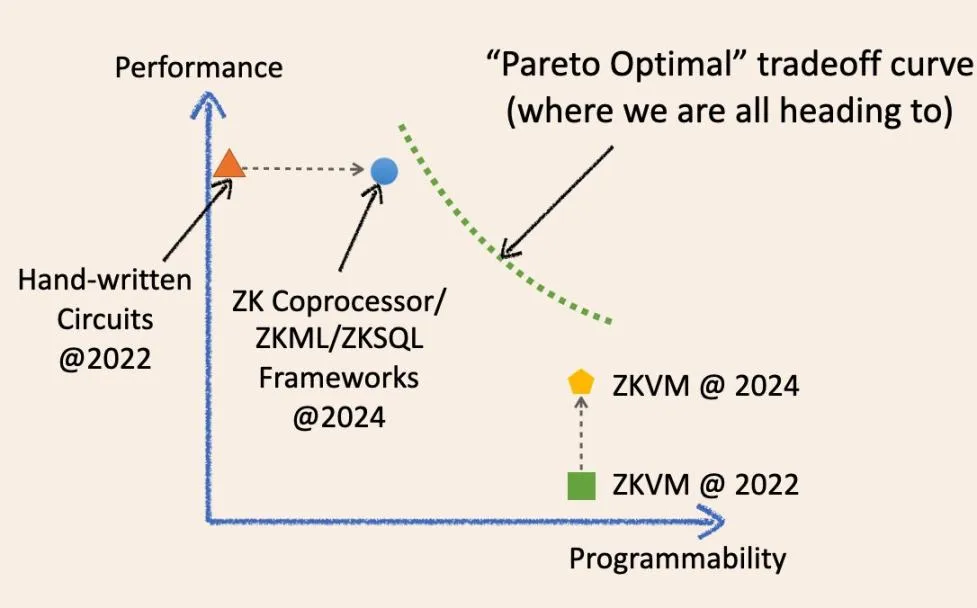
Conforme mostrado no diagrama, é possível convergirmos para um ponto ideal mágico no sistema de coordenadas de compensação no futuro?
Não, o futuro da computação verificável fora da cadeia é uma curva contínua que obscurece os limites entre ZK especializada e geral. Permita-me explicar a evolução histórica desses termos e como eles convergirão no futuro.
Dois anos atrás, a infraestrutura ZK “especializada” significava estruturas de circuito de baixo nível, como circom, Halo2 e arkworks. Os aplicativos ZK criados com essas estruturas eram essencialmente circuitos ZK escritos à mão. Eles eram rápidos e econômicos para tarefas específicas, mas geralmente difíceis de desenvolver e manter. Eles são semelhantes a vários chips de circuitos integrados especializados (wafers físicos de silício) no atual setor de CI, como chips NAND e chips controladores.
Entretanto, nos últimos dois anos, a infraestrutura ZK especializada tornou-se gradualmente mais “generalizada”.
Agora temos estruturas ZKML, coprocessador ZK e ZKSQL que oferecem SDKs fáceis de usar e altamente programáveis para criar diferentes categorias de aplicativos ZK sem escrever uma única linha de código de circuito ZK. Por exemplo, o coprocessador ZK permite que os contratos inteligentes acessem de forma confiável os estados históricos, eventos e transações do blockchain e executem cálculos arbitrários nesses dados. O ZKML permite que os contratos inteligentes utilizem resultados de inferência de IA de maneira confiável para lidar com uma ampla gama de modelos de aprendizado de máquina.
Essas estruturas evoluídas melhoram significativamente a capacidade de programação em seus domínios-alvo, mantendo o alto desempenho e o baixo custo devido a camadas de abstração finas (SDK/API) que se aproximam dos circuitos bare-metal.
Eles são semelhantes à GPU, TPU e FPGA no mercado de CI: especialistas em domínio programável.
O ZKVM também fez grandes avanços nos últimos dois anos. Notavelmente, todas as ZKVMs de uso geral são construídas sobre estruturas ZK especializadas e de baixo nível. A ideia é que você possa escrever aplicativos ZK em linguagens de alto nível (ainda mais fáceis de usar do que o SDK/API), que são compilados em uma combinação de circuitos especializados e conjuntos de instruções (RISC-V ou semelhante ao WASM). Eles são como chips de CPU no setor de CI.
O ZKVM é uma camada de abstração acima das estruturas ZK de baixo nível, assim como os coprocessadores ZK.
Como uma pessoa sábia disse certa vez, uma camada de abstração pode resolver todos os problemas da ciência da computação, mas ao mesmo tempo cria outro problema. Essa é a chave para as compensações. Fundamentalmente, para o ZKVM, trocamos desempenho e generalidade.
Há dois anos, o desempenho “bare-metal” do ZKVM era de fato ruim. Entretanto, em apenas dois anos, o desempenho do ZKVM melhorou significativamente.
Por quê?
Porque esses ZKVMs de “uso geral” se tornaram mais “especializados”. Um dos principais motivos para a melhoria do desempenho é a “pré-compilação”. Essas pré-compilações são circuitos ZK especializados capazes de computar programas comuns de alto nível, como SHA2 e várias verificações de assinaturas, com muito mais rapidez do que dividi-los em fragmentos de circuitos de instruções.
Portanto, a tendência agora é bastante clara.
A infraestrutura ZK especializada está se tornando mais generalizada, enquanto as ZKVMs gerais estão se tornando mais especializadas.
As otimizações de ambas as soluções nos últimos anos alcançaram um ponto de equilíbrio melhor do que antes: progredir em um ponto sem sacrificar outro. É por isso que ambos os lados sentem que “definitivamente somos o futuro”.
No entanto, a sabedoria da ciência da computação nos diz que, em algum momento, encontraremos a “parede ideal de Pareto” (linha tracejada verde), onde não podemos melhorar um desempenho sem sacrificar outro.
Portanto, surge uma pergunta de um milhão de dólares:
Uma tecnologia substituirá completamente a outra no momento certo?
Tomando emprestado insights do setor de CIs: o tamanho do mercado de CPUs é de US$ 126 bilhões, enquanto todo o setor de CIs (incluindo todos os CIs “especializados”) é de US$ 515 bilhões. Tenho certeza de que, de uma perspectiva micro, a história se repetirá aqui, e eles não se substituirão.
Dito isso, hoje em dia ninguém diria: “Ei, estou usando um computador totalmente acionado por uma CPU de uso geral” ou “Ei, este é um robô sofisticado acionado por CIs especializados”.
Sim, de fato devemos ver essa questão de uma perspectiva macro e, no futuro, haverá uma curva de compensação que permitirá que os desenvolvedores escolham com flexibilidade de acordo com suas necessidades.
No futuro, a infraestrutura ZK especializada e o ZKVM geral poderão trabalhar juntos. Isso pode ser realizado de várias formas. O método mais simples já pode ser realizado agora. Por exemplo, você pode usar um coprocessador ZK para gerar alguns resultados de computação no histórico de transações do blockchain, mas a lógica de negócios de computação nesses dados é muito complexa e não pode ser simplesmente expressa no SDK/API.
O que você pode fazer é obter provas ZK de alto desempenho e baixo custo dos dados e resultados de computação intermediários e, em seguida, agregá-los em uma VM de uso geral por meio de provas recursivas.

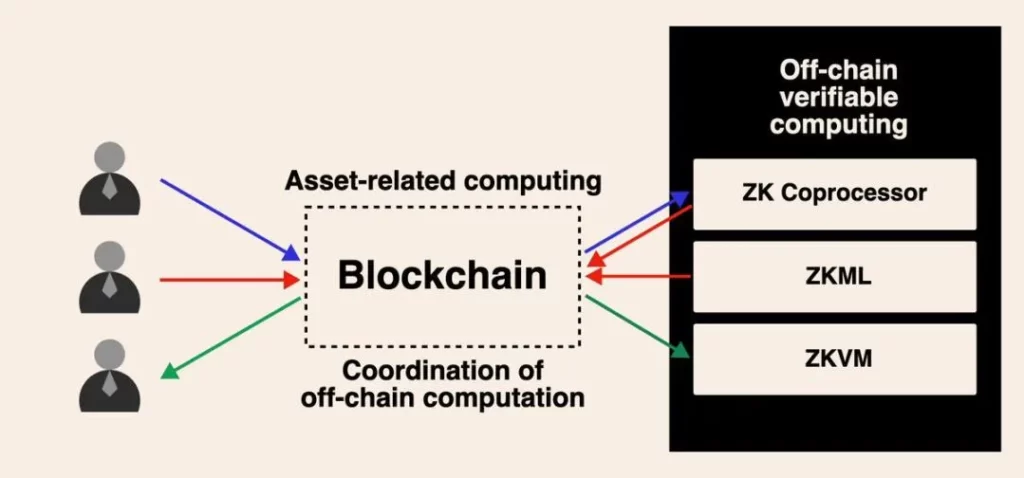
Embora eu ache esse tipo de debate interessante, sei que todos nós estamos construindo esse futuro de computação assíncrona impulsionado pela computação verificável fora da cadeia para blockchain. À medida que surgirem casos de uso para adoção em massa pelos usuários nos próximos anos, acredito que esse debate finalmente chegará a uma conclusão.
-

-

-

-

-

-

-

-

